Introducción a Machine Learning: Algunos conceptos básicos
El Machine Learning o Aprendizaje Automático es una rama de la inteligencia artificial que nace durante la segunda mitad del siglo XX. Su principal objetivo es desarrollar métodos capaces de generalizar comportamientos y reconocer patrones a partir de la información de entrada, permitiendo que computadores encuentren información y se comporten de cierta forma sin que hayan sido explícitamente programados para ello.
Hoy estamos rodeados de ejemplos de Inteligencia Artificial y de Aprendizaje Automático pero muchas veces no nos damos cuenta de ello. Aquí dejo algunos ejemplos (pueden ver algunos más en Wikipedia):
- Filtros de spam
- Reconocimiento de texto y voz (ej.: Siri, Cortana, etc.)
- Sistemas de recomendación (ej.: recomendaciones de Amazon)
- Detección de fraudes (ej.: marcar transacciones fraudulentas en tarjetas de crédito)
- Conducción automática de vehículos (reconocimiento de patrones)
Principales tipos de algoritmos de machine learning
Existen principalmente 3 tipos de algoritmos de aprendizaje automático o machine learning:
Aprendizaje supervisado (Supervised learning)
El objetivo principal del aprendizaje supervisado es identificar un modelo a partir de data de entrenamiento en la cual se conoce el valor verdadero de salida, y usar este para predecir datos futuros o desconocidos.
Un ejemplo son los filtros de spam, donde a partir de un set de correos electrónicos marcados correctamente como SPAM / NO-SPAM, se entrena un modelo para determinar qué etiqueta se debe asignar a un próximo correo revisando el valor/contenido de sus atributos (contenido, asunto, remitente, etc.).
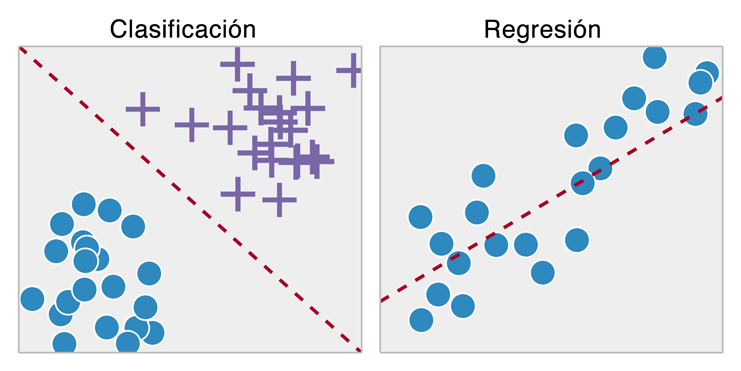
La Clasificación es una sub-categoría del aprendizaje supervisado donde el objetivo es predecir etiquetas o clases. Estas etiquetas son valores discretos no ordenados que pueden ser entendidos como categorías. El ejemplo del SPAM previamente mencionado es un Clasificador Binario, aunque esto es válido para clasificadores más complejos. En este contexto, un clasificador solo puede predecir en función los valores que fue entrenado. Por ejemplo, si a un clasificador le enseña un abecedario no podrá reconocer números del 0-9 si estos no son parte del set de entrenamiento.
Las Regresiones también son una sub-categoría de los algoritmos de aprendizaje supervisado, pero se utilizan en la predicción de valores continuos. En el análisis de regresiones, se entrega un número o números (predictor) que explican el valor de salida, es decir, los valores de entrada guardan relación con la variable a explicar. Dentro de las regresiones, la más común es la regresión lineal, que mediante una ecuación de primer orden busca explicar un valor de salida.
Aprendizaje por refuerzo (Reinforcement learning)
El aprendizaje por refuerzo busca desarrollar sistemas (agent) que mejoren su desempeño a partir de interacciones con su entorno. Como el estado actual del entorno típicamente incluye información del desempeño de una acción (reward signal) se puede pensar el reinforcement learning como un tipo aprendizaje supervisado. Sin embargo, el reward signal no es el dato o valor correcto asociado el estado del entorno sino que es una medida de que tan bien se desempeñó la acción tomada. Un sistema puede tomar esta medida de éxito y mediante múltiples intentos (por ensayo y error o planeados) maximizar su recompensa.
Un ejemplo de aprendizaje por refuerzo podría ser un motor de ajedrez. Aquí el agente o sistema toma una serie de decisiones en base al estado actual del tablero (environment) y la señal de recompensa (reward signal) puede ser entendida como ganar o perder el juego. Al jugar múltiples veces, el agente cada vez se vuelve mejor para ello (o por lo menos esa es la idea).
Aprendizaje no supervisado (Unsupervised learning)
En los algoritmos de aprendizaje supervisado, conocemos la respuesta correcta de antemano y con esto entrenamos un sistema. En el aprendizaje por refuerzo, definimos una función que nos indica que tan buen desempeño tiene una acción en el entorno, lo que permite ir mejorando el desempeño del sistema. Lamentablemente en el aprendizaje no supervisado no contamos con esta información, acá trabajamos con datos no etiquetados (ej.: spam vs. no-spam) o con estructuras completamente desconocidas. El aprendizaje no supervisado nos entrega herramientas para explorar y extraer información relevante de la estructura sin tener conocimiento previo.
Un ejemplo de aprendizaje no supervisado es la búsqueda de sub-grupos mediante el clustering. El clustering es una técnica de exploración que nos permite agrupar datos de forma significativa sin conocimiento previo de ellos. Los elementos de cada grupo que emergen tiene cierta similitud, pero que son mayormente disímiles con los otros sub-grupos. Un ejemplo práctico sería la clasificación (no supervisada) de clientes para dirigir de mejor forma las acciones de marketing en una compañía.
Otro sub-campo del aprendizaje no supervisado es la reducción de dimensionalidad para la compresión de datos. En ocasiones, los datos vienen con un gran número de dimensiones (o atributos) que puede dificultar su almacenamiento. En estas situaciones, la reducción de dimensionalidad permite descartar las dimensiones que no son suficientemente relevantes para predicción, esto permite ahorrar espacio y tiempo de procesamiento. Por esto, muchas veces se hace durante la etapa de pre-procesamiento de datos. En otras ocasiones, queremos graficar los datos en 1, 2 o 3D, para esto también nos puede ser útil.
Para terminar
Entrar al mundo de machine learning es poco árido debido a la cantidad y complejidad de las disciplinas que involucra (programación, estadística, big data, etc.). Es probable que una introducción como esta deje más dudas que respuestas, pero si mantenemos las ganas aprender, iremos en la dirección correcta. Ánimo y hasta la próxima!